
Introduction
One important area of responsibility for public authorities is infrastructure maintenance, which includes repair work on road surfaces. Manual inspection of road surfaces is time-consuming and therefore potentially costly. With the rapid development of deep learning methods in recent years, road damage can now potentially be detected automatically. Here we present a project that aims to enable the automatic detection of potholes, cracks, and open manholes on roads. This is done using frames from video streams, which are created by cell phone recordings taken while riding a bicycle or by garbage collection vehicles.
Methods
Data handling and preparation
We used a publicly available dataset from Kaggle, which we downloaded using the Kaggle API. Our data includes more than 3000 road images featuring potholes, cracks and open manholes, as well as images without any defects. We then split the data into train data (70%), validation data (10%) and test (20%) data.
The dataset that we use already has augmented images, e.g. rotated images, black and white versions of our images etc. This allows our model to learn more robust features and generalize better to unseen, real-world data, as well as be less prone to overfitting during training.
Model architecture
Two different model architectures were trained with the aim of comparing them.
The first architecture was Detection Transformer (DETR) with a residual neural network 50 (ResNet-50) as its backbone, the older architecture of the two. A model trained on the COCO object detection dataset was used, which was fine-tuned on the road defects data.
The second architecture was version 8 of You Only Look Once (YOLOv8), using size s. The more recent YOLOv8s is significantly more efficient than DETR and therefore potentially better suited for real-time object detection and training on limited resources.
Training strategies
Two basic methodologies were tested to detect road damage (potholes, cracks, and open manholes) in images and locate them via bounding boxes.
In an initial attempt, pre-trained models were adapted to our data using transfer learning. This approach has the advantage that the weights of the models are not random, but can already recognize certain structures, thus saving computing time.
After finishing transfer learning, the same model architectures were used again, but trained from scratch. This significantly increases the computing time for training, but there are more opportunities to influence the model and thus better understand it.
Results & Discussion
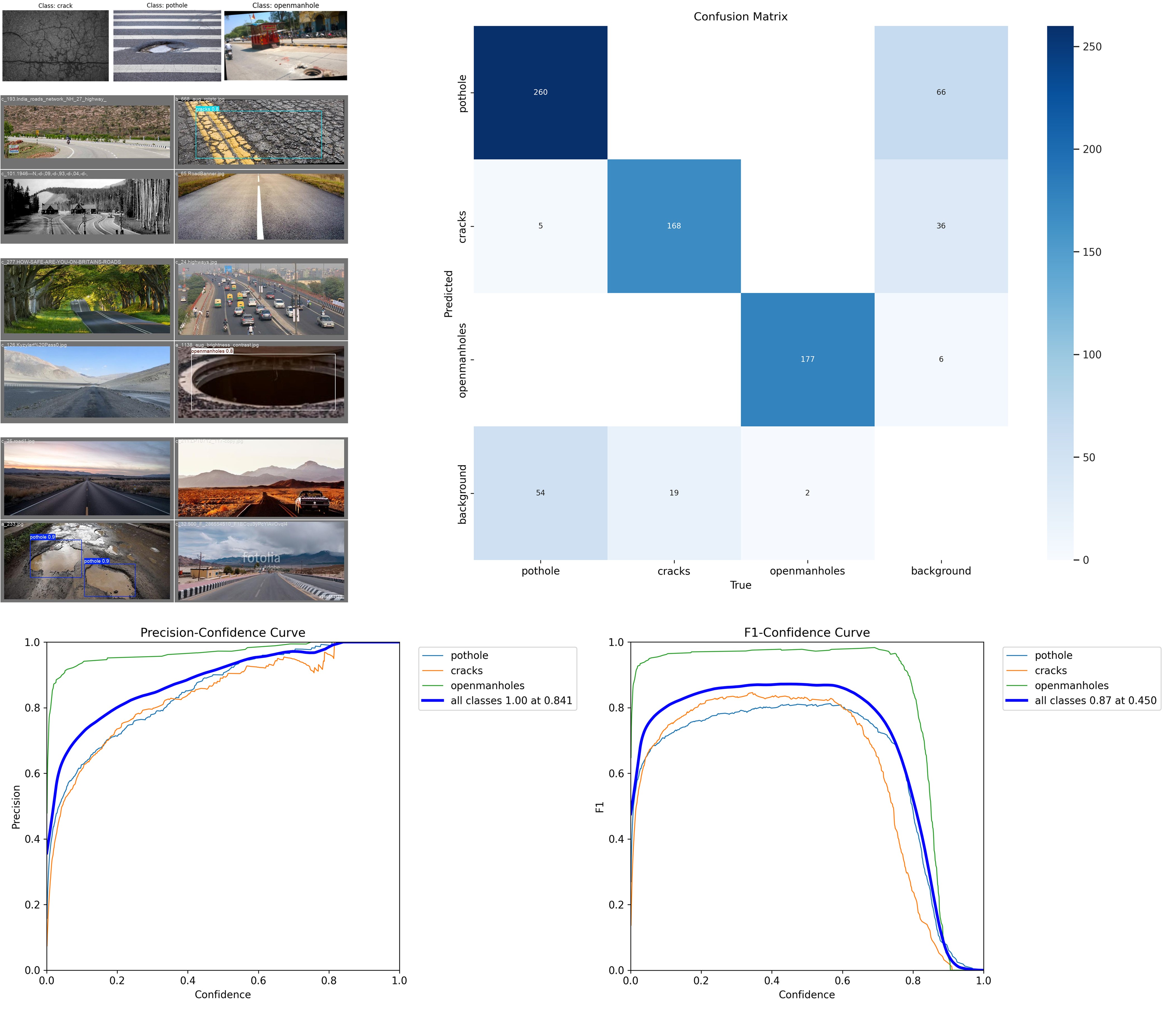
YOLOv8s performed better than DETR ResNet-50, which in this particular case can be attributed to the fact that DETR ResNet-50 required more GPU computing time for training than was provided by Google Colab. Even with caching the training results and using the transfer learning method, there was not enough time to train DETR ResNet-50 sufficiently; less than half of the objects were correctly detected (average precision on large objects = 0.29, average recall on large objects = 0.419). This means that only YOLOv8s is suitable for our objective, unless more resources are available. This problem was so far-reaching that no training success was achieved with DETR ResNet-50 at all in later training from scratch. This also applied when ResNet-32 was used as the backbone instead of ResNet-50 and the image size was drastically reduced.
YOLOv8s, trained from scratch, had no problems recognizing the classes correctly. However, there was room for improvement when the image contained only background, i.e., no identifiable object, and when it came to placing the bounding boxes correctly if the objects were located near the corners of the images. These weaknesses of the model can be explained by the fact that, compared to the classes to be recognized, there were few images without objects of interest and the objects were rarely located in the corners of the images. The class mismatch can be remedied by adding more images of intact roads, and the problems with objects in the corners can be remedied by an adapted augmentation strategy in which the images with any objects they may contain are randomly shifted.
After improving the parts discussed, the model should be tuned for a high average precision, because when sending notifications to the city, it is more important not to overwhelm employees with false positives and thus get annoyed and lose trust in the model than to simply detect the pothole the next time someone drives by.
Our best model, wich was used for the application, was a pre-trained YOLOv8s model, fine tuned via transfer learning on our data. It achieved a mean average precision (mAP) at intersection over union (IoU) thresholds from 0.50 to 0.95 (mAP50-95) of 0.512 and a mAP50 of 0.904 with a precision of 0.908 and a recall of 0.841. The best performing class was open manhole (mAP50-95 = 0.628), followed by pothole (mAP50-95 = 0.464) and cracks (mAP50-95 = 0.444). This model is sufficiently good to be applied. If we set the confidence threshold to 0.841, we can completely rule out false positive classifications, at least in our test data. The best balance between recall and precision is achieved with a confidence threshold of 0.45.
What we learned
In this project, we gained practical and theoretical experience in the development of deep learning models for object detection.
Model Architectures and PyTorch
One of the main things we learned was how to actually implement Convolutional Neural Networks (CNNs) and train them using the PyTorch framework. Theoretically, we learned how layers like convolutions and attention mechanisms work to extract features from images. Comparing ResNet-50 DETR and YOLOv8 showed us the difference between older, heavier architectures and modern detectors that are designed for speed. We also learned how to build our own architectures from scratch, which helped us understand how weight initialization works and why it is so much harder to train a model without any pre-existing knowledge.
The Role of Transfer Learning
During our project we dedicated a lot of time to Transfer Learning. We learned that instead of starting from zero, we can take a model that already knows how to recognize shapes (like the ones trained on the COCO dataset) and "fine-tune" it for our specific road defects. This taught us how feature extraction layers can be reused across different tasks to save a lot of time and computing power.
Optimization and Avoiding Overfitting
Finally, we learned how to improve our results by tuning hyperparameters, such as the learning rate and batch size. We spent some time learning about overfitting, which happens when a model performs perfectly on training data but fails on the test data. To prevent this, we used several techniques:
Data Augmentation: Using the rotated and filtered images to make the model more flexible.
Validation Sets: Using the 10% validation split to check the model’s progress during training.
Regularization: Making sure the model doesn't get too complex for the amount of data we have.
Overall, the project showed us how to move from a theoretical understanding of neural networks to a working application that can be successfully applied to real-world problems.
Sources:
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 779–788).
Team

Julian

Vincent
Vlad
Mentor:in

Nils Uhrberg




